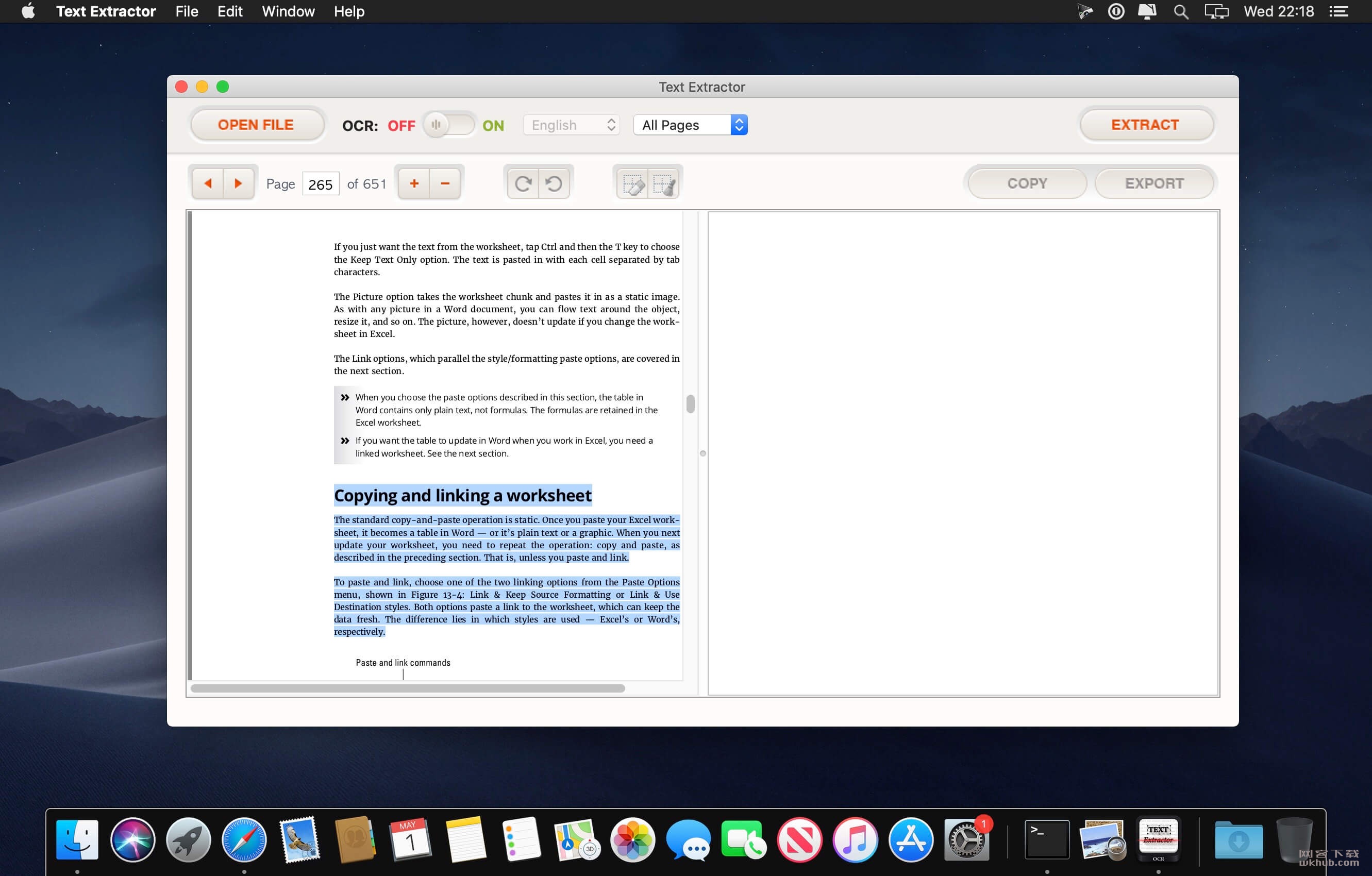
Text Extractor可帮助您将扫描的PDF文档和图像转换为可搜索和可编辑的文本内容。它可以通过先进的OCR(光学字符识别)技术消除您的重新输入工作,该技术可以准确地识别图像中的文本并有效地提取文本内容。
为什么需要文本提取器
使用扫描仪扫描纸质文档时,实际上整个内容将被捕获为图像而不是文本和字体信息。这就是为什么你不能从这种类型的文件中选择和复制文本的原因。如果您想获取信息,重新输入它们会很令人沮丧。使用文本提取器,您可以轻松获取和使用锁定在扫描文件中的信息。
高级OCR功能
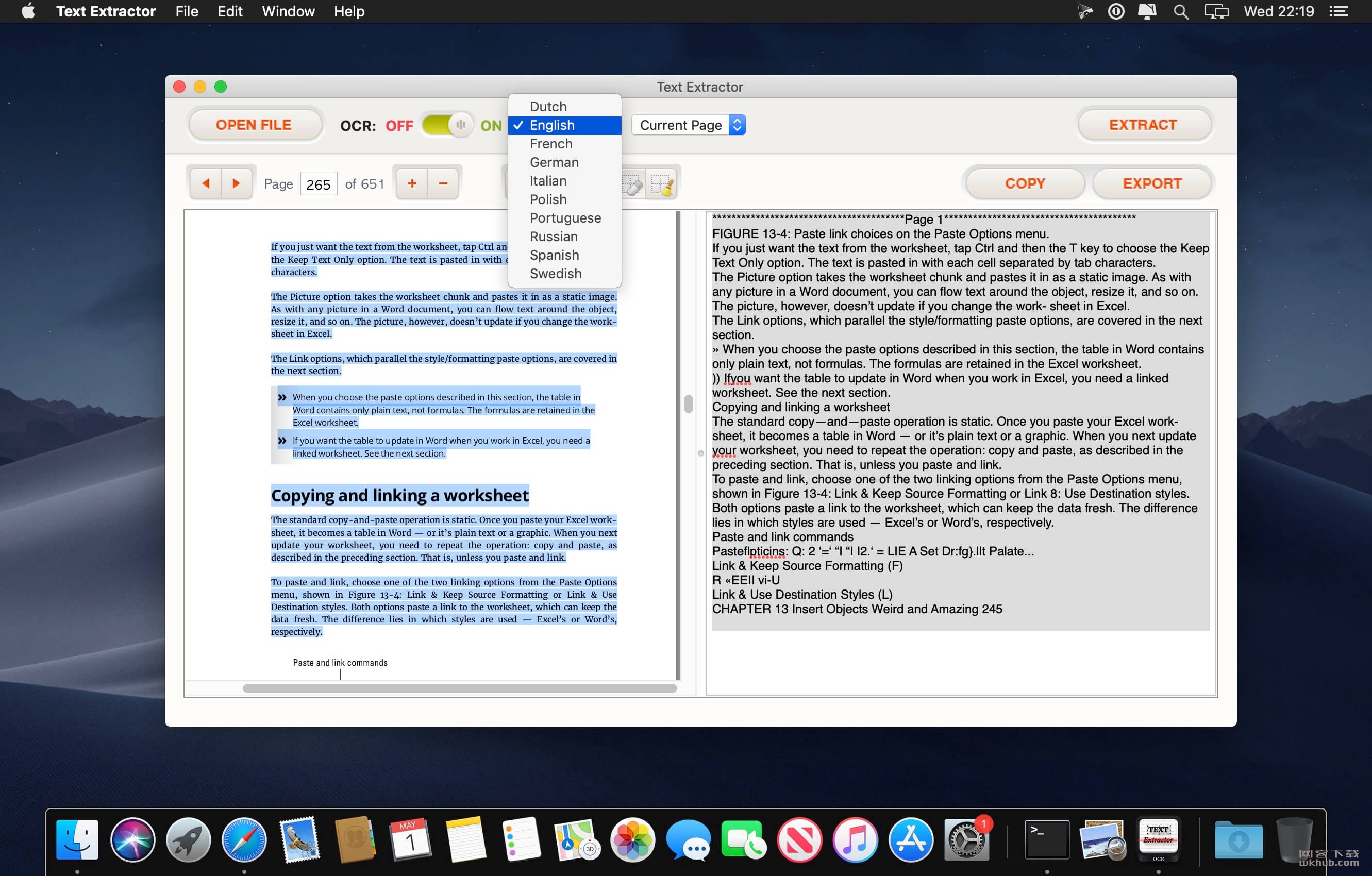
借助先进的OCR功能,如果源文件具有高质量,Text Extractor的识别准确度最高可达90%。转换后节省时间纠正错误。文本提取可以检测10种语言,包括英语,法语,德语,意大利语,瑞典语,俄语,波兰语,荷兰语,西班牙语和葡萄牙语。
直观的界面,易于使用的
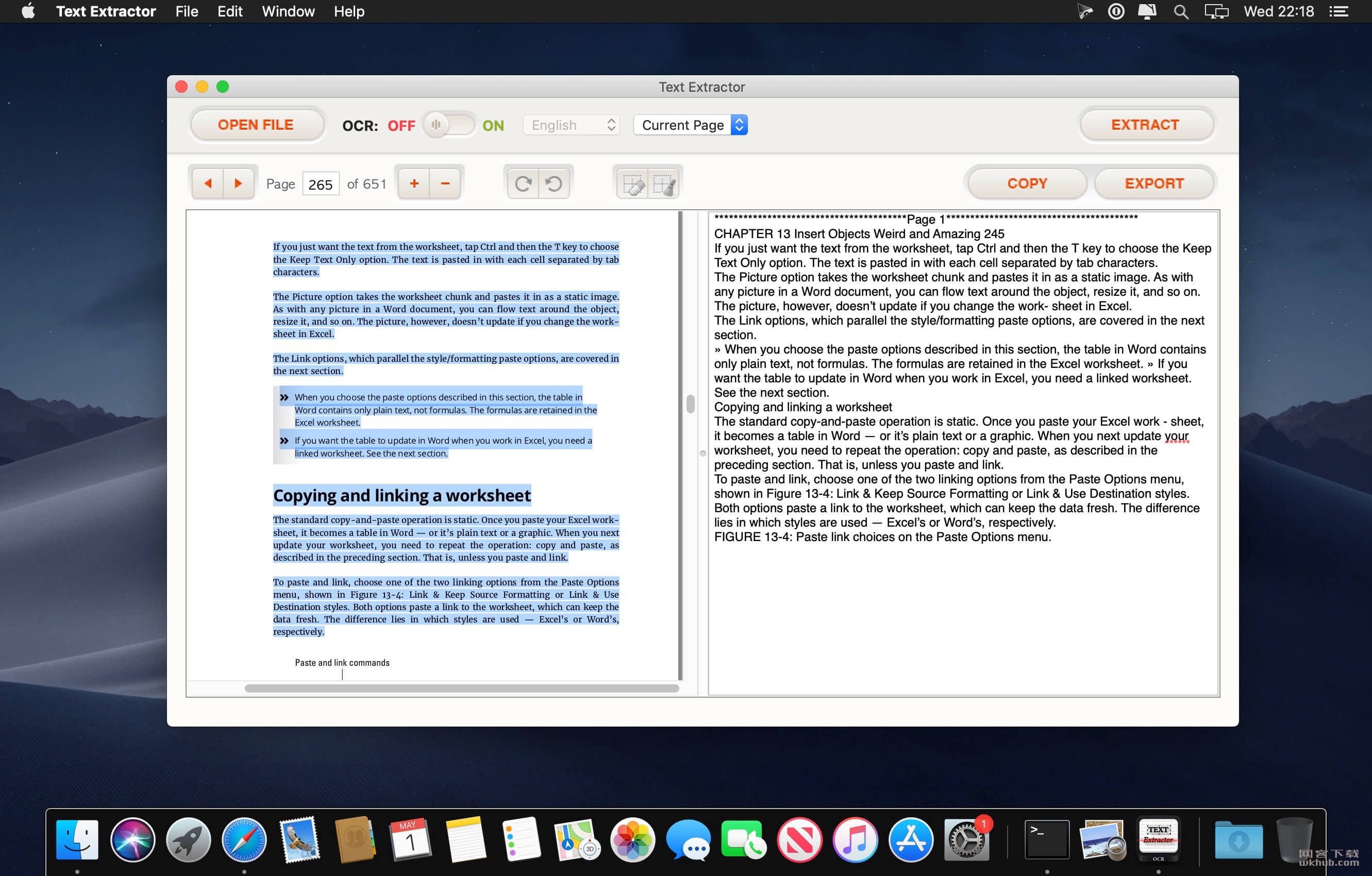
OCR转换并非易事,但通过易于使用的界面,您可以直接在内置文本编辑器中轻松执行OCR转换,编辑和修改提取的文本。然后,您可以将内容复制到剪贴板,并毫不费力地将其导出为纯文本(.txt)。
本站统一解压密码:wkhub.com
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



